Today a post about calculating averages of departments and these measures are compared to a specific department. I have a requirement to build a report with a graph with values for a specific department. Another demand is to build a line in the graph with averages of all (?) of the departments of the organization. The report must allow the user to select the department from a dropdown list in a report parameter. Based on the selected department the report should show measures for the selected department and an average of all departments.
There is an extra 'dimension'(!) in this investigation and that is how an average is calculated when we are dealing with a M2M dimensions. As you may know from my former posts M2M dimensions are specific parts of the star schemas methodology and SSAS:
- SSAS/KIMBALL: modeling a N:M relation between dimensions (part I)
- SSAS/Kimball : building a multivalue dimension construction in SSAS (part II)
- SSAS: Joining issue with MDXing of M2M dimension (part III)
- SSAS/SSRS/MDX : Cascading parameters and M2M dimensions
- SSAS/SSRS : Building a graph for analyzing a subset related to the whole set
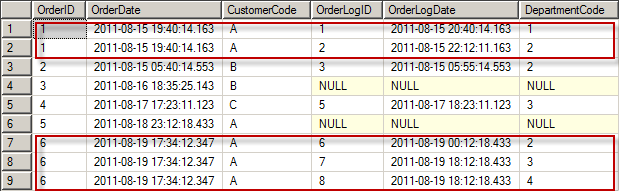
For this post i've created a lab environment for studying the average calculation of factrecords regarding M2M dimensions. I've used the same script from the post:"SSAS/SSRS : Building a graph for analyzing a subset related to the whole set". I've build a cube on these tables and it has the following structure:

Let's investigate the values in the relational tables before we investigate the OLAP cube with MDX. For this investigation w'll focus on department G and the year 2009.
1) Aggregating the results by year
In this first investigation of the totals by year shows that the FacTestCount is summarized to 35. This is a simple query and there is no involvement of the bridge table and the department dimension.

2) Aggregating the results by year by location
In this testquery i've added an extra dimension to the query: DimLocation. As you may have expected nothing changes because the location dimension is a 'normal' dimension. No cartesian product takes place (as will happen when we include the DimDepartment dimension in the next query).

3) Aggregating the results by year by location by Department
In the next query i've included the table DimDepartment and the bridgetable BridgeLocationDepartment and now something happens to the results: for the year 2009 the results have changed from 35 to 62. Because of the cartesian product we now have 62.

4) Aggregating the results by year by Department G
As earlier mentioned in this post w'll focus on Department G and the year 2009. In the query below you can see that we have 14 as the result of the query (for the year 2009):

Building the MDX statements
When building reports based on cubes you need to write MDX to get the data from the cube. This paragraph starts with an easy MDX query :

That is the result we would have expected because the SQL query returns also 14 for the year 2009 for department G. Now we need to write an MDX query that calculates the average (and summarization) of all departments by year. Below you can see the query i've written to calculate the following items:
- [Measures].[Fact Test Count]. This measure is the count field in the fact and is used for summarizing (rolling up).
- [Measures].[SUM Fact Test Count]. This a measure where the Fact Test Count is summarized by year and by department.
- [Measures].[AVG Fact Test Count Found Departments]. This measure is calculated by taking the average of the departments that have a factrecord (and not all of departments present in the department dimension).
- [Measures].[AVG Fact Test Count All Departments]. This measure calculates the average over all of the departments that are available in the Department dimension. Even when there a less records in the fact present related to a department.
- [Measures].[AVG Fact Test Count All Departments2]. This measure is just a test of mine whether i could call a another Calculated member.

Okay what do we see now? We can see that the total of all departments in the year 2009 is equal to the cartesian product SQL query above (62). So that's is a desired outcome. The average by found department is 7.75 (62/8) and these are departments that do have a factrecord. The next measure is 6.2 and that is 62/10 because there 10 departments in the department dimension.
Building the report
The next thing to do is building a report with this MDX query. In this report i want to show the selected parameter in a graph and compare this to the average of departments and the sum. Perhaps not a best usability practice of building a graph but this just for showing what is possible with MDX averages, sums and graphs in reports. First build a report, create a datasource to the cube and build a dataset based on the query above. And the next thing is dragging a graph from the toolbox in the report and customize it as below. I've used the average by all departments for comparison of the chosen department in the parameter.


I'm not fully convinced whether i've used the right presentation of the values. I've to think about this ;-) What can we learn from such a diagram? Well, there are two years that the measure was below average and the other years showed a higher level than the select department. It depends on the context of the data what this mean, offcourse. If you're talking about profits then that it's a good thing. If you're talking about a number defects then it's a bad thing.
Conclusion
This post is about investigating the calculation of averages in relation with M2M dimensions. This post helped me understanding what is going on when i calculate an average of departments in MDX with M2M dimensions. In a discussion with my customer we talked about it and we were curious about what is being calculated in a report when an average is calculated. Does it calculate an average of the unique values or the values that multiplied by the cartesian product, does it calculate the averages over the found departments or the departments that are present in the department dimension.
Hennie








































{kind=link}
{kind=link}
{kind=link}